Big Data es, sin duda, uno de los conceptos tecnológicos más importante de los últimos años. Alrededor de este nuevo paradigma tecnológico han aparecido nuevas profesiones que tienen una gran demanda en el mercado laboral: ingeniero/arquitecto de datos (data engineer) y analista/científico de datos (data scientist).
Las tecnologías que emergieron en este campo se centraron en proporcionar capacidades de almacenamiento y procesamiento de grandes cantidades de datos a los ingenieros y analistas de datos. El trabajo de estos profesionales se ha centrado en el diseño de arquitecturas escalables y la utilización de algoritmos de analítica avanzada sobre esos datos almacenados. Hadoop y Spark son las tecnologías estrellas para desarrollar aplicaciones dentro de este paradigma denominado batch processing, caracterizado por la ejecución de procesos complejos, de larga duración, sobre grandes cantidades de datos
Pero Big Data está entrando en una nueva era donde la capacidad de procesar información online y la rapidez de respuesta es la clave. Las empresas cada vez identifican más necesidades de este tipo, así como las ventajas que este paradigma de procesamiento puede aportarles. Es lo que se denomina streaming processing. Procesar información generada en tiempo real proveniente, por ejemplo, de sensores (Internet of Things), redes sociales o logs, abre un nuevo abanico de posibilidades en múltiples escenarios como detección de fraude, análisis de comportamiento de usuario o monitorización.
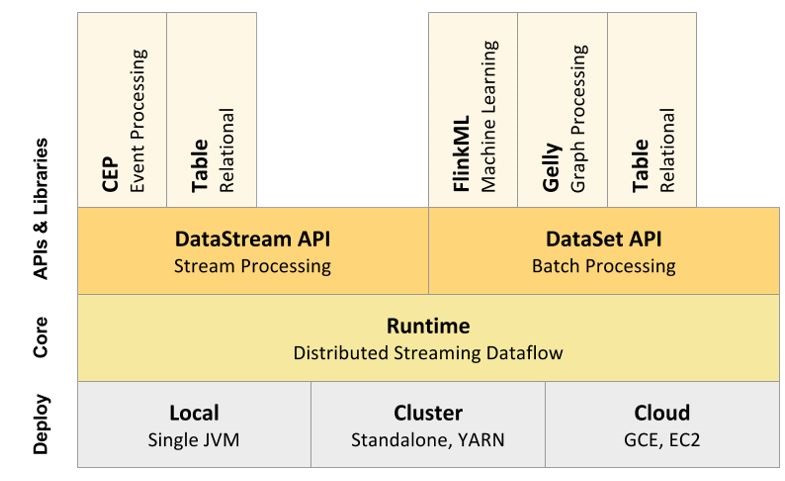
Es en esta nueva realidad tecnológica donde desembarca Apache Flink. Apache Flink es una plataforma open source y escalable para el procesamiento distribuido de datos masivos. El núcleo de Flink es un motor de streaming processing que permite tanto el procesamiento de datos generados en tiempo real como de datos estáticos (batch processing). Apache Flink es, sin duda, la tecnología estrella de este paradigma de procesamiento diferenciándose notablemente de sus competidores (Spark Streaming, Storm, Samza, Apex, etc.) por sus principales características:
- Utilización de un enfoque de procesamiento event-at-time y no micro-batching permitiendo respuestas en tiempo real.
- API específico y sencillo para batch processing (DataSet) y streaming processing (DataStream) en diferentes lenguajes de programación (Java, Scala y Python)
- Posibilidad de utilizar sintaxis SQL para el análisis de datos (Table).
- Gestión avanzada del concepto tiempo, permitiendo el procesamiento de eventos desordenados (event time y processing time)
- Procesamiento avanzando de ventanas por tiempo, nº de elementos y sesiones, incluyendo mecanismos de customización como Triggers y Evictors permitiendo el diseño de complejas lógicas de negocio.
- Soporte nativo de operaciones incrementales optimizando los procesos de graph analytics y machine learning.
- Gestión eficiente de la memoria gracias a su gestor de memoria específico dentro de la JVM.
- Optimización automática de las aplicaciones gracias a sus optimizadores específicos para batch y streaming processing.
- Perfecta integración con el ecosistema Big Data (Hadoop, Kafka, HBase, etc.).
- Ecosistema nativo a su alrededor creciendo incluyendo librerías para Complex Event Procesing (CEP), Graph Analytics (Gelly) y Machine Learning (FlinkML).
Si eres programador, arquitecto o analista de datos y quieres adelantarte a la nueva evolución tecnológica del Big Data, no puedes perderte este curso donde aprenderemos de la mano de los mejores expertos del sector el uso de Apache Flink desde cero. No es necesario conocimientos ni experiencias en tecnologías Big Data, simplemente el conocimiento de Java o Scala y las ganas de aprender esta fabulosa herramienta. En este curso se enseñará:
- Conceptosbásicos sobre qué es streaming processing y las diferencias arquitectónicas con los sistemas tradicionales
- Instalación y configuración de Apache Flink así como de su entorno de desarrollo
- Dataset: el API para desarrollar aplicaciones batch processing con Apache Flink
- DataStrem: el API para desarrollar aplicaciones straeming processing con Apache Flink
- Programación avanzada con Apache Flink
- Integración de Apache Flink con Hadoop, Kafka y otras tecnologías Big Data
- Implementación práctica de casos de estudio
- Gelly: introducción al procesamiento de grafos con Apache Flink
- Gestión en producción de un clúster de Apache Flink
El artículo Nuevo curso Escuela Big Data Science: Apache Flink fue escrito el 8 de septiembre de 2016 y guardado bajo la categoría Big Data. Puedes encontrar el post en el que hablamos sobre .
Esta formación te puede interesar
Curso de Google Analytics 4
Curso
1 mes
{{start_date}}
Nuestros cursos
Máster en Analítica Digital
Define KPIs, domina GA4 y usa datos en decisiones clave
Master
8 meses
{{start_date}}
Máster de Inteligencia Artificial aplicada a Negocio
Aplica IA de forma estratégica en cualquier empresa
Master
7 meses
{{start_date}}
Máster en Project Management (PMP)
Lidera la dirección y gestión de proyectos con metodología PMI® para certificarte en (PMP)®
Master
6 meses
{{start_date}}
Descrubre nuestros cursos

22 · 10 · 2025
Automatización de procesos con IA: la clave para la eficiencia y la innovación
Si quieres optimizar tus procesos y la eficiencia de tu negocio, la IA puede ayudarte a conseguirlo. Te contamos cómo funciona la automatización de procesos con IA y cómo puedes utilizarla como una ventaja competitiva para tu negocio. ¿Qué es la automatización de procesos? La automatización de procesos se basa en usar sistemas informáticos que […]

21 · 10 · 2025
La IA que te hace Pensar
En las últimas semanas se han publicado diferentes informes que analizan el uso de la Inteligencia Artificial en España (Observatorio Anual IAon, así como, el informe Así Somos), con datos interesante sobre el uso de la IA: el 88,3 % de la población dice conocerla y el 51 % la ha usado. Pero el uso […]

21 · 10 · 2025
Qué es el Deep Learning: la inteligencia artificial que transforma el mundo
La tecnología al servicio del ser humano avanza cada vez más rápido. Quien dispone de datos dispone de multitud de información que puede ser útil para muchos ámbitos de la vida, desde la medicina hasta la empresa. ¿Imaginas poder analizar todos los datos del mundo en pocos segundos y lograr establecer una relación lógica entre […]

02 · 10 · 2025
Apps IA que transformarán tu 2025 | KSchool
Las aplicaciones de IA son cada vez más comunes, facilitan tus tareas y te ayudan a mejorar tu rendimiento en el trabajo y en tu día a día, pero ¿quieres descubrir cuáles son realmente útiles para ti y cómo pueden ayudarte a transformar la forma en la que desempeñas tu trabajo? Te lo contamos. Las […]