
En otras ocasiones ya os hemos hablado sobre los Trabajos de Fin de Máster de nuestros alumnos de Data Science, y hoy volvemos a hacerlo. Sergio Valmorisco Sierra es un ingeniero de telecomunicación apasionado por la ciencia de datos que decidió matricularse en el Máster de Data Science de KSchool para mejorar su conocimiento sobre los fundamentos y las últimas tecnologías de la ciencia de datos. A continuación nos cuenta en detalle su experiencia realizando el TFM calificado con un 10. ¡Cómo se lo curran nuestros KSchooleros!
El TFM de Data Science que realicé en KSchool tenía como objetivo el desarrollo de un modelo de predicción del precio final de un tipo especial de subastas denominadas “pay-per-bid”.
Este tipo de subastas se caracterizan por la peculiaridad de que cada puja individual supone un coste fijo para el usuario que la realiza, independientemente de que termine ganando la subasta o no. El ganador de la subasta suele obtener el producto por un precio bastante menor al de mercado, y la mayoría de las ganancias de los organizadores de la subasta provienen del coste de las pujas realizadas y no del precio final alcanzado por el producto.
Con el TFM pretendía cubrir el ciclo completo de un proyecto de ciencia de datos: adquisición de los datos, limpieza y preparación de los datos, análisis y finalmente visualización de resultados. Además, quería aplicar el amplio conocimiento adquirido en el máster sobre diferentes campos de la ciencia de datos.
Con estos objetivos en mente, comencé a buscar datos públicos que tuvieran la suficiente calidad y, tras una larga búsqueda, encontré datos recogidos por unos investigadores sobre Swoopo, una de las páginas web comerciales más famosas de subastas pay-for-bid.
Los datos estaban divididos en dos ficheros. El primero de ellos contenía información general sobre más de un millón de subastas reales realizadas en Swoopo, incluyendo la descripción del producto ofrecido, su precio de mercado en el momento de la subasta, el precio final de venta, el nombre del usuario ganador, el número de pujas realizadas en cada subasta, etc. El segundo fichero contenía información detallada sobre más de 7000 de estas subastas, como el instante de tiempo de cada puja individual, el nombre del usuario que realizó cada puja, etc.

Aprende Data Science
Aprende a analizar y aprovechar los datos de tu empresa para tomar decisiones más informadas y estratégicas
Primero procedí a limpiar los datos y a analizarlos para obtener información estadística general. En la parte de análisis encontré algunos hechos interesantes. Por ejemplo, el precio final alcanzado era menor que el precio de mercado para el 47.50% de las subastas, aunque en media Swoopo obtenía 200$ por encima del precio de mercado de cada producto subastado. En media, el ganador de la subasta compraba el producto por 160$ menos que su precio de mercado. Las pujas de los ganadores de las subastas representaban en media el 20% de todas las pujas de cada subasta.
Después del análisis y partiendo de los datos obtenidos tras un proceso de limpieza, decidí realizar un modelo de predicción del precio final de cada subasta, pudiendo calcular la eficacia del modelo comparando los resultados de las predicciones con los precios finales alcanzados en la realidad de acuerdo a los datos con que contaba.
El modelo trataba de predecir el valor de una variable (en este caso, el precio final alcanzado en la subasta) a través de otras variables de entrada conocidas al comienzo de la subasta. Para obtener buenos resultados, era clave escoger variables de entrada apropiadas que fueran capaces de explicar el comportamiento de la variable a predecir con la máxima precisión posible.
Los productos subastados en Swoopo eran en su gran mayoría artículos de consumo electrónico tales como videojuegos, televisores, ordenadores portátiles, móviles, reproductores de música, etc. Los datos contaban con una descripción del producto, por ejemplo «PSP Slim & Lite Sony Piano Black». Sin embargo, no contenían una descripción de la categoría a la que pertenecía, como podría ser “Video Games & Consoles” para el ejemplo anterior. Como se ha mencionado anteriormente, era clave escoger variables de entrada apropiadas para el modelo de predicción, e introducir información de la categoría a la que pertenecía cada producto podía ser una información que mejorase en gran medida las predicciones.
Amazon.com es una de las grandes compañías de comercio electrónico y vende o vendía la gran mayoría de los productos contenidos en los datos. Además, siempre asigna una categoría a los productos que vende, la cual podía ser útil para completar la información de los datos. Para el ejemplo de «PSP Slim & Lite Sony Piano Black» la categoría asignada por Amazon es «Video Games > Sony PSP > Consoles». Usé técnicas de web scraping para obtener la categoría de todos los productos contenidos en los datos. Estas técnicas sirven para extraer información de páginas web de forma automatizada, en este caso basándose en el hecho de que la categoría asignada por Amazon a sus productos se encuentra siempre bajo el mismo identificador HTML (lenguaje de programación usado en el desarrollo de páginas web) para todos sus productos.
La idea era que las categorías de los productos asignadas por Amazon sirviesen como información de entrada al modelo de predicción para poder separar los productos en grupos en función de su categoría y buscar posibles patrones de precio final diferentes para cada categoría. No obstante, Amazon cuenta con muchos tipos de categorías, además de categorías diferentes pero muy similares entre sí, como por ejemplo “Video Games › PlayStation 3 › Games” y “Video Games › Wii › Games”. Para que la información de la categoría de producto fuese realmente útil para el modelo de predicción era necesario definir distancias entre las categorías que indicasen lo similares o diferentes que eran.

En el campo de procesamiento de lenguaje natural (PLN o NLP en inglés), el modelo previamente entrenado Word2Vec de Google incluye vectores de palabras para un vocabulario de 3 millones de palabras que entrenaron con una base de datos de Google News. Cada palabra se representa como un vector de 300 valores, creando así un espacio multidimensional donde las palabras similares o relacionadas se encuentran representadas por puntos cercanos. Cada categoría de producto de Amazon estaba compuesta por varias palabras, y por ello, se calculó un vector para cada una de ellas que se obtuvo como la media de los vectores de cada una de las palabras que contenía. Así, cada categoría quedaba representada por un único vector, y era posible distinguir entre categorías similares o diferentes basándose en las distancias entre estos vectores. Los algoritmos de agrupamiento (clustering en inglés) permiten agrupar una serie de vectores de acuerdo a un criterio, en este caso la distancia. Se usó el algoritmo de clustering K-Means para crear clusters (grupos) de productos con la misma categoría o categorías similares basándose en la distancia de los vectores.
Para el modelo de predicción, decidí usar varias técnicas y algoritmos de predicción, para así poder comparar múltiples resultados y encontrar la mejor combinación posible.
Comparé 5 técnicas diferentes:
- Un único modelo de predicción sin usar como entrada la información obtenida de las categorías de los productos.
- Un único modelo de predicción usando clusters basados en las categorías de los productos.
- Múltiples modelos de predicción, donde cada uno de ellos se correspondía a cada cluster obtenido basándose en las categorías de los productos.
- Un único modelo de predicción usando clusters no sólo basados en las categorías de los productos, sino también en su precio de mercado.
- Múltiples modelos de predicción, donde cada uno de ellos se correspondía a cada cluster obtenido básandose tanto en las categorías de los productos como en su precio de mercado.
Además de los clusters en los casos correspondientes, todos los modelos usaban como datos de entrada el precio de mercado del producto, el incremento del precio final de la subasta por cada puja realizada, el coste unitario por puja en que incurrían los usuarios, y unos identificadores que indicaban el tipo de subasta (Swoopo clasificaba sus subastas en diferentes tipos, siendo algunas de ellas subastas restringidas a usuarios que todavía no habían ganado ninguna, otras con precio final fijo, etc.).
De los algoritmos de predicción analizados, los que mejores resultados dieron fueron los basados en bosques aleatorios (random forests). Se obtuvieron mejores resultados con los modelos que usaban clusters para las categorías de los productos que los que no tenían en cuenta la información de las categorías. En cuanto a las dos opciones de clustering consideradas, la que mejor resultados dio fue la que calculaba los clusters basándose sólo en la categoría de los productos sin tener en cuenta su precio de mercado.
Así, finalmente, los mejores resultados se obtuvieron con un único modelo de predicción usando clusters basados únicamente en las categorías de los productos. Como métricas de calidad del algoritmo de predicción, se obtuvo un error absoluto mediano de 10.37$ y un error absoluto medio de 28.29$ en las predicciones.
A la hora de evaluar los valores de las métricas calculadas, hay que tener en cuenta que el precio final de una subasta puede depender de muchos factores: los usuarios que estén monitorizando la subasta, el dinero con el que cuentan y sus intereses en el momento de la subasta, etc. Los datos contenían múltiples subastas del mismo producto, y se observaba que incluso cuando el producto era el mismo, el precio que se alcanzaba en cada una de las subastas era muy diferente, haciéndolo así algo difícilmente predecible.
Para facilitar el análisis visual de los datos también se creó un dashboard interactivo con Tableau:
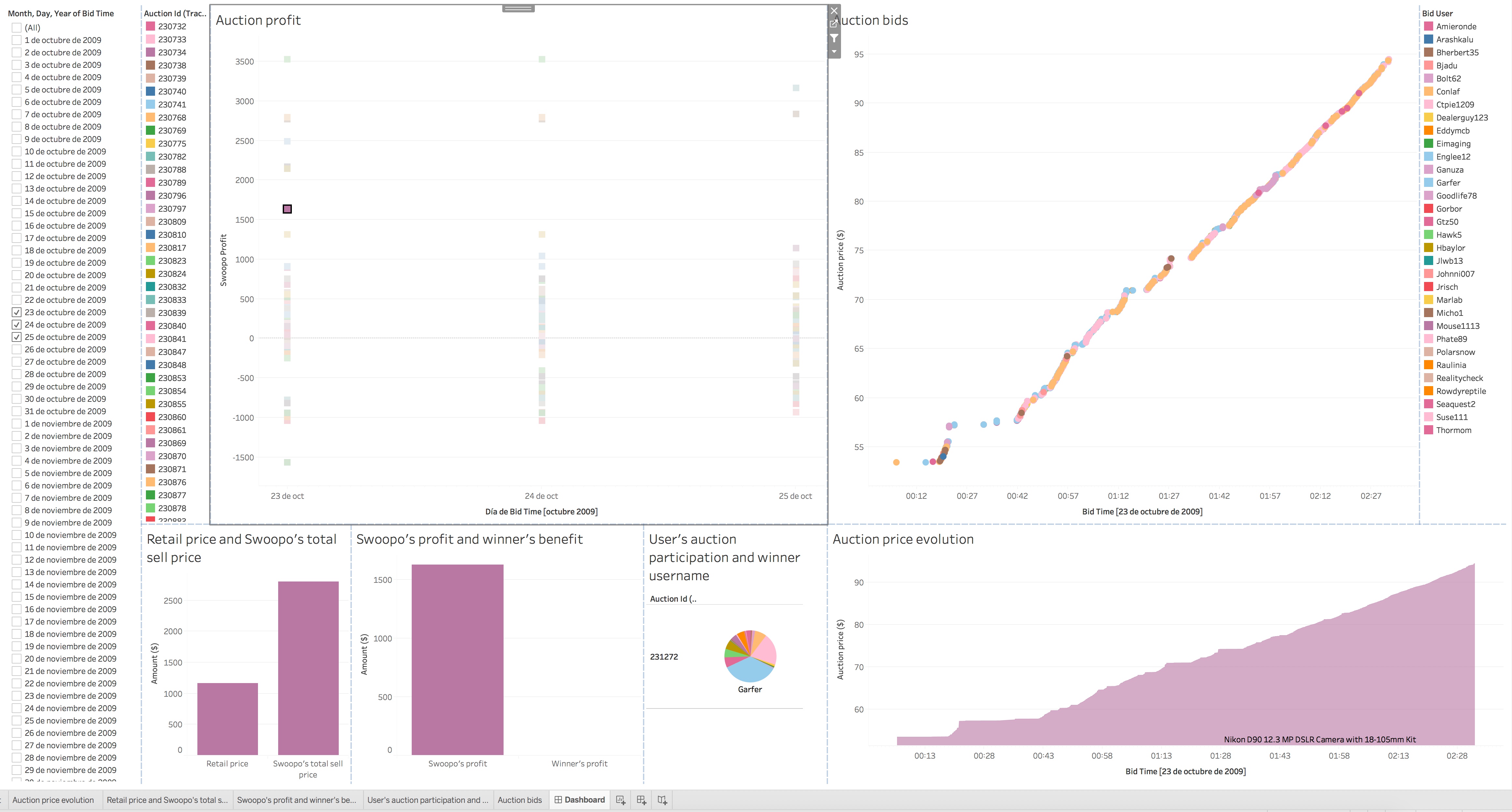
De este modo, el TFM me permitió practicar el ciclo completo de un proyecto de ciencia de datos y cubrir diferentes técnicas relacionadas con la ciencia de datos, como web scraping, análisis de datos, procesamiento del lenguaje natural, algoritmos de clustering, algoritmos de predicción, herramientas de visualización de datos, etc.
Si queréis profundizar en el código y en el resto del proyecto podéis acceder al repositorio del TFM en GitHub aquí.
[dt_sc_callout_box type=»type4″ icon=»fa-pencil» link=»#ffc72c» target=»_blank» button_text=»»]
Más información sobre el Máster de Data Science
[/dt_sc_callout_box]
Escrito por Sergio Valdemorisco, exalumno del Máster de Data Science de KSchool
El artículo Un TFM del Máster de Data Science de 10: Predicción de precios finales de subastas fue escrito el 14 de noviembre de 2019 y actualizado por última vez el 10 de octubre de 2024 y guardado bajo la categoría Data Science. Puedes encontrar el post en el que hablamos sobre Sergio Valmorisco, exalumno del Máster de Data Science de KSchool, nos cuenta todo acerca del TFM que le valió un 10..
Esta formación te puede interesar
Máster en Analítica Digital
Define KPIs, domina GA4 y usa datos en decisiones clave
Master
8 meses
Otoño
Máster en Cloud CRM Marketing
En colaboración con SIDN Digital Thinking, partner oficial de Salesforce
Master
8 meses
Otoño
Curso de Google Analytics
Conviértete en experto en GA4
Curso
1 mes
Próximamente
Nuestros cursos
Máster en Analítica Digital
Define KPIs, domina GA4 y usa datos en decisiones clave
Master
8 meses
Otoño
Máster en Cloud CRM Marketing
En colaboración con SIDN Digital Thinking, partner oficial de Salesforce
Master
8 meses
Otoño
Curso de Google Analytics
Conviértete en experto en GA4
Curso
1 mes
Próximamente
Descrubre nuestros cursos

02 · 09 · 2024
¿Qué es un Data Scientists? Funciones y cómo trabajar de ello
¿Te has preguntado alguna vez qué hace un data scientist y cómo puedes convertirte en uno? Te contamos todo lo que necesitas saber sobre los científicos de datos: sus funciones, habilidades necesarias y los pasos a seguir para trabajar en este campo. ¿Qué es un data scientist? Un data scientist o científico de datos es […]

13 · 09 · 2024
El 2024 es el año de la IA: Tendencias para 2024
El año 2024 se presenta como clave para la Inteligencia Artificial, te contamos cuáles son las principales tendencias en IA en 2024. Una tecnología que pasará a formar parte de cada vez más ámbitos de nuestra vida y que promete la automatización de muchos procesos aumentando con ellos la eficacia en cualquier tarea. Tendencias de […]

15 · 04 · 2024
¿Cuál es la diferencia entre Data Science vs Data Analytics?
En la actualidad existen muchas disciplinas que presentan similitudes y diferencias entre ellas, lo que puede llevar a confusión a la hora de saber cuáles son las funciones que realizan cada uno de los profesionales que se dedican a ellas por ello queremos resolver tus dudas sobre cuál es la diferencia entre Data Science y […]
15 · 04 · 2024
Herramientas para Data Scientists: las más habituales
¿Quieres sacarle el máximo partido al Data Scientist? Para ello es necesario conocer cuáles son las herramientas más habituales y qué usos tienen cada una de ellas. Te mostramos cuáles son las esenciales para que puedas aprovechar al máximo todo lo que la ciencia de datos puede aportarte. Herramientas para Data Scientist Las herramientas par […]