
The Signal and the Noise; Why So Many Predictions Fail but Some Don’t es un influyente libro de Nate Silver, que alcanzó la fama por sus predicciones de las elecciones presidenciales de EE.UU. Los datos no son otra cosa: una combinación de señal y de ruido, de categoría y de anécdota, de grano y paja.
La tarea del científico de datos ahora, igual que la del estadístico desde hace más de un siglo, consiste en separar la una del otro, extraer los patrones repetibles y repetidos sin dejarse engañar por los aleatorios. La estadística, la ciencia de datos, se reducen a eso. Cuando no lo consiga, sus predicciones fallarán.
Ciencia de datos es lo que hace un estadístico que programa, que sabe enfrentarse solventemente los conjuntos de datos a los que nos tiene acostumbrados el siglo XXI. O lo que hace un programador que aprendió la estadística necesaria para ver el bosque y no solo los árboles.
Hace unos pocos días, tenía un conversación por correo electrónico con un un científico de datos, exalumno del Máster de Data Science de KSchool, que quería profundizar en los detalles de un algoritmo muy usado en márketing analítico: el del multi armed bandit. Es el algoritmo que, precisamente, subyace a uno de los productos de Google Analytics. Por supuesto que está soportado por la increíble infraestructura de datos de Google. Pero utiliza ideas que se conocen y usan en el mundo de la estadística desde hace dos siglos: la estadística bayesiana.
Las herramientas de Google para medir el impacto causal de, por ejemplo, campañas publicitarias, también está basado en un desarrollo de la misma teoría. ¿Hace falta conocerla para usar esas herramientas? No. Pero sí para adaptarlas a un contexto similar pero no exactamente igual. Aunque, por supuesto, también necesitaremos saber programarlas.
¿Hasta dónde se puede llegar sin estadística en la ciencia de datos? Desgraciadamente, no muy lejos. Los recetarios de técnicas de machine learning incluyen muchos programas y trucos que permiten, incluso, llegar a obtener algún éxito parcial en plataformas como Kaggle. Pero un paseo por sus foros, una discusión con algunos de quienes participan en ellas, revela que muchos se limitan a dar tumbos sin criterio, sin una idea clara de qué quieren conseguir y, muy particularmente, cómo. Revela crueldad, pero cuando pienso en ellos siempre me vienen a la cabeza estas dos palabras: script kiddie.
La teoría, la estadística en este caso, no es nunca un corsé que aprieta sino una guía que orienta. Las herramientas de ciencia de datos, muchas y poderosas, que uno puede encontrar implementadas en Python, R o Spark son genéricas. Valen para todo pero, en el fondo, para nada. Cuando las enseño en KSchool, lo reconozco aquí, me cuesta encontrar conjuntos de datos de ejemplo en los que poder aplicarlas tal cual, sin ningún tipo de adaptación específica al caso concreto. Pero después, en la vida real, el valor reside en la capacidad de lidiar con esos impedimentos concretos y específicos del problema en cuestión. Es, como abría el párrafo, la teoría la que orienta.
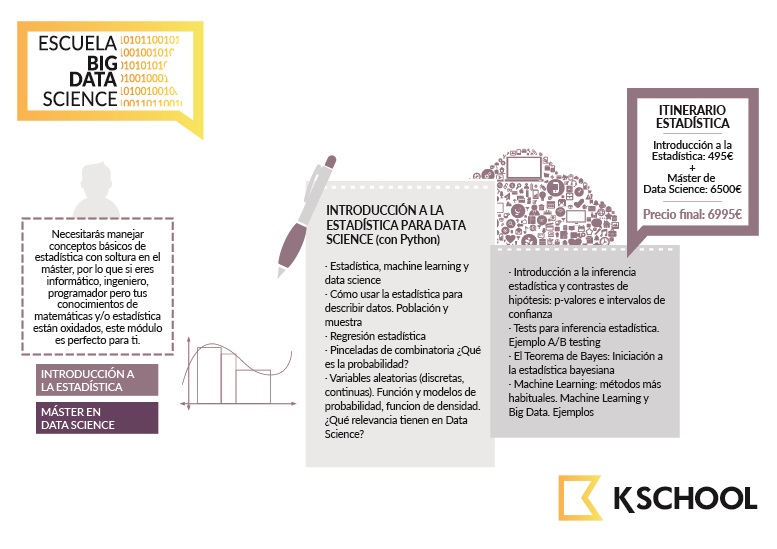
El programa del máster de Data Science de KSchool dedica algunas sesiones a profundizar en en la estadística. Son, por necesidad, pocas. Pero están pensadas (como, de hecho, gran parte del programa) como una base sobre la que construir y ahondar. Ponen al científico de datos en el camino del proceso de aprendizaje constante.
Si no tienes esta base, desde la propia escuela, se ha preparado un programa previo de estadística para que el alumno pueda aprender toda la base necesaria para poder seguir el ritmo del Máster y aprovecharlo al máximo.
Hoy mismo he visto que el exalumno al que me refería más arriba publicaba en su Twitter una foto de su nueva adquisición: un libro de estadística bayesiana para hackers. Seguro que lo hace mejor programador, mejor estadístico y, necesariamente, mejor científico de datos.
Carlos Gil Bellosta
El artículo ¿Hasta dónde se puede llegar en el Data Science sin estadística? fue escrito el 15 de noviembre de 2016 y guardado bajo la categoría Data Science. Puedes encontrar el post en el que hablamos sobre .
Esta formación te puede interesar
Curso de Big Data Marketing
Aprende todo lo que el Big Data puede hacer por tu estrategia de marketing
Curso
2 meses
Próximamente
Curso de Data Driven Design
Con este curso aprenderás a diseñar productos digitales basados en datos cuantitativos y cualitativos
Curso
2 meses
Próximamente
Programa en People Analytics y HR Analytics
Crea y usa modelos efectivos en recursos humanos
Titulación conjunta con:

Curso
5 meses
Otoño
Nuestros cursos
Máster en Data Science
Domina las mejores técnicas de análisis de datos
Master
8 meses
Otoño
Máster en Product Manager
Aprende a liderar la estrategia, creación y evolución continua de productos con foco en marketing
Titulación conjunta con:
Master
7 meses
Otoño
Máster en Marketing Digital
Impulsa tu carrera profesional y empleabilidad en Marketing Digital con KSchool
Master
5 meses
Otoño
Descrubre nuestros cursos

02 · 09 · 2024
¿Qué es un Data Scientists? Funciones y cómo trabajar de ello
¿Te has preguntado alguna vez qué hace un data scientist y cómo puedes convertirte en uno? Te contamos todo lo que necesitas saber sobre los científicos de datos: sus funciones, habilidades necesarias y los pasos a seguir para trabajar en este campo. ¿Qué es un data scientist? Un data scientist o científico de datos es […]

13 · 09 · 2024
El 2024 es el año de la IA: Tendencias para 2024
El año 2024 se presenta como clave para la Inteligencia Artificial, te contamos cuáles son las principales tendencias en IA en 2024. Una tecnología que pasará a formar parte de cada vez más ámbitos de nuestra vida y que promete la automatización de muchos procesos aumentando con ellos la eficacia en cualquier tarea. Tendencias de […]

15 · 04 · 2024
¿Cuál es la diferencia entre Data Science vs Data Analytics?
En la actualidad existen muchas disciplinas que presentan similitudes y diferencias entre ellas, lo que puede llevar a confusión a la hora de saber cuáles son las funciones que realizan cada uno de los profesionales que se dedican a ellas por ello queremos resolver tus dudas sobre cuál es la diferencia entre Data Science y […]
15 · 04 · 2024
Herramientas para Data Scientists: las más habituales
¿Quieres sacarle el máximo partido al Data Scientist? Para ello es necesario conocer cuáles son las herramientas más habituales y qué usos tienen cada una de ellas. Te mostramos cuáles son las esenciales para que puedas aprovechar al máximo todo lo que la ciencia de datos puede aportarte. Herramientas para Data Scientist Las herramientas par […]