
Juan Bernardo Gómez (@juanbert) y Michael Ellner (@mikeellner) desarrollaron una aplicación web capaz de describir ciertos aspectos de las tendencias de búsqueda de Google (SQ) con información disponible en Twitter como Trabajo de Fin de Máster de Data Science de KSchool y que ya tienen publicado en Github para que los más curiosos podáis verlo por aquí.
Cuando alguien hace una búsqueda en Google, lo que obtiene una lista de páginas web relacionadas con su búsqueda y ordenadas según el criterio del algoritmo de Google.
Mientras tanto, Twitter es una aplicación con micro-blogs y cada tweet representa una actualización del estado personal del dueño del perfil, entonces se podría decir que cada tweet representa una opinión personal del administrador de la cuenta.
Aclarados estos conceptos y basándose en Google Trends, (una interesante herramienta que permite medir los tópicos «trending» en búsquedas de Google, y posteriormente analizar que es ese algo que puede haber causado los picos de búsqueda) querían poder describir lo mismo pero con Twitter.
Y había 3 factores que fueron capaces de describir en este análisis:
1) -> Generación de contenido relacionado en twitter y las cantidad de impresiones o tweets hechos, a lo largo del tiempo
2) -> Análisis de Opinión a través de procesamiento de lenguaje natural
3) -> Ubicación de las personas detrás de las cuentas de twitter que han generado el contenido
Detrás de Escenas (tecnología)
- ETL (Extract transform and Load)
Desarrollaron un proceso ETL para poder disponibilizar los datos que necesitaban las diferentes funcionalidades analíticas previamente mencionadas. La aplicación está basada en datos no estructurados y Mongodb era la tecnología indicada para este caso.
Toda la información se manejó como objetos con formatos json, desde que era extraída de las diferentes fuentes hasta que era cargada en la base de datos.
Algunos ejemplos ejemplos de un objeto por fuente de datos podrían ser:
Google trend:
«`python
db.google_hottrends.find_one()
«`
«`javascript
{u’_id’: ObjectId(‘580f771d9bb0062a76e06d3f’),
u’dateTime’: datetime.datetime(2016, 10, 25, 17, 15, 41),
u’formated_time’: u’Tue_Oct_25_17_15_41_2016′,
u’geo’: u’ES’,
u’qs’: [u’Praga’,
u’Copa del Rey’,
u’Antoni Van Leeuwenhoek’,
u’Pete Burns’,
u’France Football’,
u’Fox’,
u’FastPokeMap’,
u’Los Otros Dos’,
u’San Rafael’]}
«`
Tweet:
«`python
db.tweets.find_one()
«`
«`javascript
{u’_id’: ‘790720412531433472L’,
u’contributors’: None,
u’coordinates’: None,
u’created_at’: u’Tue Oct 25 01:03:31 +0000 2016′,
u’dateTime’: datetime.datetime(2016, 10, 25, 1, 3, 31),
u’entities’: {u’hashtags’: [],
u’symbols’: [],
u’urls’: [],
u’user_mentions’: []},
u’favorite_count’: 1,
u’favorited’: False,
u’geo’: None,
u’id_str’: u’790720412531433472′,
u’in_reply_to_screen_name’: None}
«`
2. Asi, obtuvieron dos tipos de extracción de información para el análisis:
Estructurada:
Una la línea de tiempo de las impresiones de google trends y la cuenta de tweets para cada google trend. Aplicando una agregación a nivel de fecha obtenemos las datos y luego graficándolo en d3.js. Por ejemplo:
No-Estructurada:
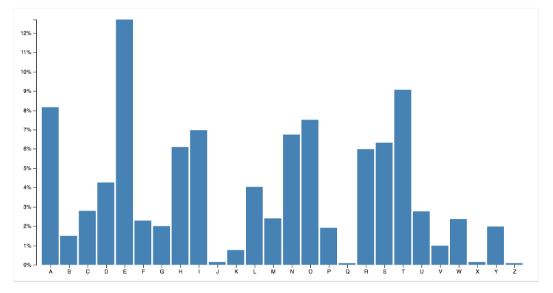
Procesamiento de lenguaje natural: el análisis consiste en una cuenta de palabras para los tweets más recientes relacionados a un Google Trend. Una serie de procesamientos preceden a la cuenta de palabras eliminado artículos, preposiciones, palabras comunes y URLs publicadas con los tweets que no agregan información o desviaban el resultado. Por ejemplo:

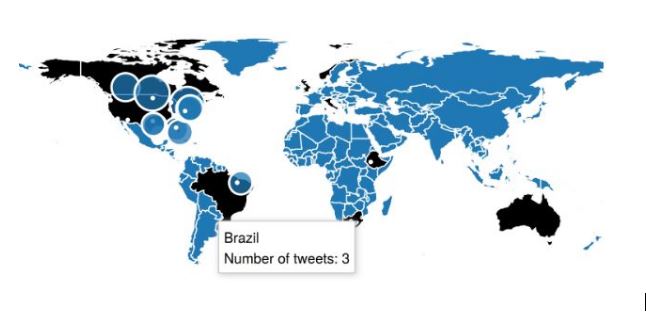
Ubicación geográfica de los tweets: La mayoría de las cuentas de twitter tienen la ubicación en coordenadas vacías. Aun así hay un campo en las descripción de perfil que llamado «Location» escrito por el administrador de la cuenta. Por ejemplo:
__New York__
..*New York City,
..*New York City, US
..*The Big Apple
..*Nueva York
Así que la única manera de asociar estas palabras con una coordenada era mapeando cualquier posible combinación de nombres para una ciudad usando un conjunto de datos que contenía los posibles valores (para este conjunto de datos acudieron a Internet :)). Por ejemplo:
Tecnología empleada:
- __Jupyter notebooks:__
Donde mostramos código y los gráficos relacionados con el análisis.
- __Web Page ()__ Desarrollamos una página web con capacidades análiticas, el modo más accesible para hacer público este tipo de análisis.
* __Flask:__ for the backend of the web page to deliver services for the html and javascript. Values shown in the frontend are retrieved from here as well there is an API to feed the D3.js objects
El backend de la página web está construido en este framework. Donde renderizamos el html y javascript, desarrollamos controladores con funciones para cada una de las vistas disponibles. Además los gráficos eran alimentados con APIs tambíen construida en flask.
* __D3.js:__ para transformar valores numéricos en pixeles, D3.js hace el trabajo excelente y en internet hay miles de ejemplos disponibles.
* __DataMaps:__ una librería de D3 especializada en mapas (para mostrar la ubicación de los tweets)
* __Bootstrap:__ Librerías muy ágil para construir páginas web.
Dicho esto, si queréis profundizar en el código y en el resto del proyecto podéis acceder al repositorio del TFM en Github aquí y si además queréis más información sobre el Máster de Data Science para conseguir crear desarrollos tan útiles como éste de Juan Bernardo y Michael, ya sabéis: info@kschool.com
[dt_sc_button type=»type1″ link=»https://kschool.com/cursos/master-en-data-science-madrid» size=»medium» bgcolor=»#dfdedc» textcolor=»#000000″ target=»_new» timeline_button=»no»]Quiero más información del Máster de Data Science[/dt_sc_button]
El artículo TFM Data Science: Describiendo tendencias de búsquedas en Google utilizando tweets relacionados fue escrito el 15 de marzo de 2017 y guardado bajo la categoría Data Science. Puedes encontrar el post en el que hablamos sobre .
Esta formación te puede interesar
Curso de Big Data Marketing
Aprende todo lo que el Big Data puede hacer por tu estrategia de marketing
Curso
2 meses
Próximamente
Curso de Data Driven Design
Con este curso aprenderás a diseñar productos digitales basados en datos cuantitativos y cualitativos
Curso
2 meses
Próximamente
Programa en People Analytics y HR Analytics
Crea y usa modelos efectivos en recursos humanos
Titulación conjunta con:

Curso
5 meses
Otoño
Nuestros cursos
Máster en Data Science
Domina las mejores técnicas de análisis de datos
Master
8 meses
Otoño
Máster en Product Manager
Aprende a liderar la estrategia, creación y evolución continua de productos con foco en marketing
Titulación conjunta con:
Master
7 meses
Otoño
Máster en Marketing Digital
Impulsa tu carrera profesional y empleabilidad en Marketing Digital con KSchool
Master
5 meses
Otoño
Descrubre nuestros cursos

02 · 09 · 2024
¿Qué es un Data Scientists? Funciones y cómo trabajar de ello
¿Te has preguntado alguna vez qué hace un data scientist y cómo puedes convertirte en uno? Te contamos todo lo que necesitas saber sobre los científicos de datos: sus funciones, habilidades necesarias y los pasos a seguir para trabajar en este campo. ¿Qué es un data scientist? Un data scientist o científico de datos es […]

13 · 09 · 2024
El 2024 es el año de la IA: Tendencias para 2024
El año 2024 se presenta como clave para la Inteligencia Artificial, te contamos cuáles son las principales tendencias en IA en 2024. Una tecnología que pasará a formar parte de cada vez más ámbitos de nuestra vida y que promete la automatización de muchos procesos aumentando con ellos la eficacia en cualquier tarea. Tendencias de […]

15 · 04 · 2024
¿Cuál es la diferencia entre Data Science vs Data Analytics?
En la actualidad existen muchas disciplinas que presentan similitudes y diferencias entre ellas, lo que puede llevar a confusión a la hora de saber cuáles son las funciones que realizan cada uno de los profesionales que se dedican a ellas por ello queremos resolver tus dudas sobre cuál es la diferencia entre Data Science y […]
15 · 04 · 2024
Herramientas para Data Scientists: las más habituales
¿Quieres sacarle el máximo partido al Data Scientist? Para ello es necesario conocer cuáles son las herramientas más habituales y qué usos tienen cada una de ellas. Te mostramos cuáles son las esenciales para que puedas aprovechar al máximo todo lo que la ciencia de datos puede aportarte. Herramientas para Data Scientist Las herramientas par […]